
Despite the remarkable progress in text-to-image generative models, they are prone to adversarial attacks and inadvertently generate unsafe, unethical content. Existing approaches often rely on fine-tuning models to remove specific concepts, which is computationally expensive, lack scalability, and/or compromise generation quality. In this work, we propose a novel framework leveraging k-sparse autoencoders (k-SAEs) to enable efficient and interpretable concept manipulation in diffusion models. Specifically, we first identify interpretable monosemantic concepts in the latent space of text embeddings and leverage them to precisely steer the generation away or towards a given concept (e.g., nudity) or to introduce a new concept (e.g., photographic style). Through extensive experiments, we demonstrate that our approach is very simple, requires no retraining of the base model nor LoRA adapters, does not compromise the generation quality, and is robust to adversarial prompt manipulations. Our method yields an improvement of 20.01% in unsafe concept removal, is effective in style manipulation, and is ~5x faster than current state-of-the-art.
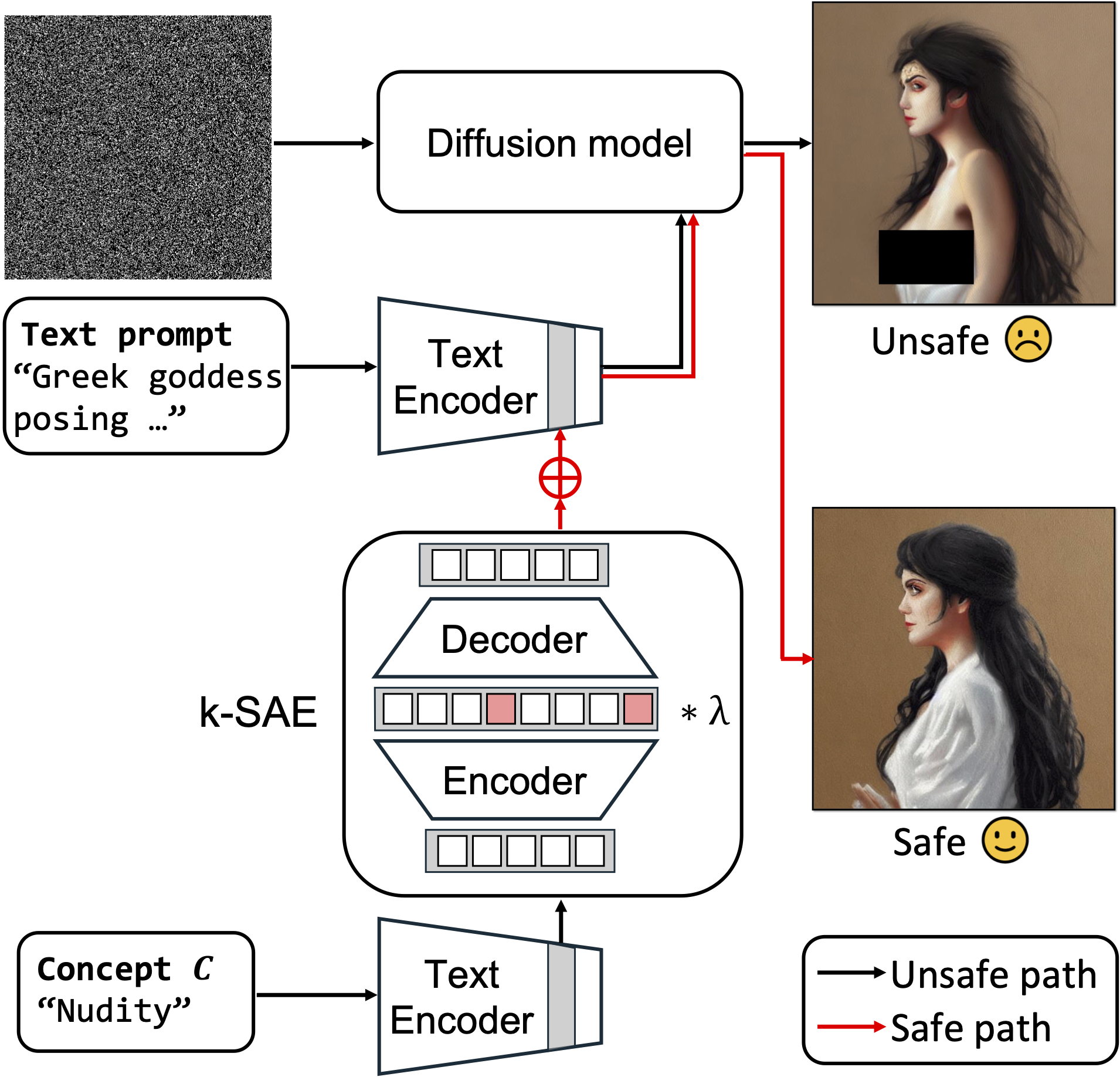
K-sparse autoencoder (k-SAE) is trained on feature representations from the text encoder of the diffusion model. Once trained, it serves as a Concept Steerer, enabling precise, surgical concept manipulation by adjusting λ.
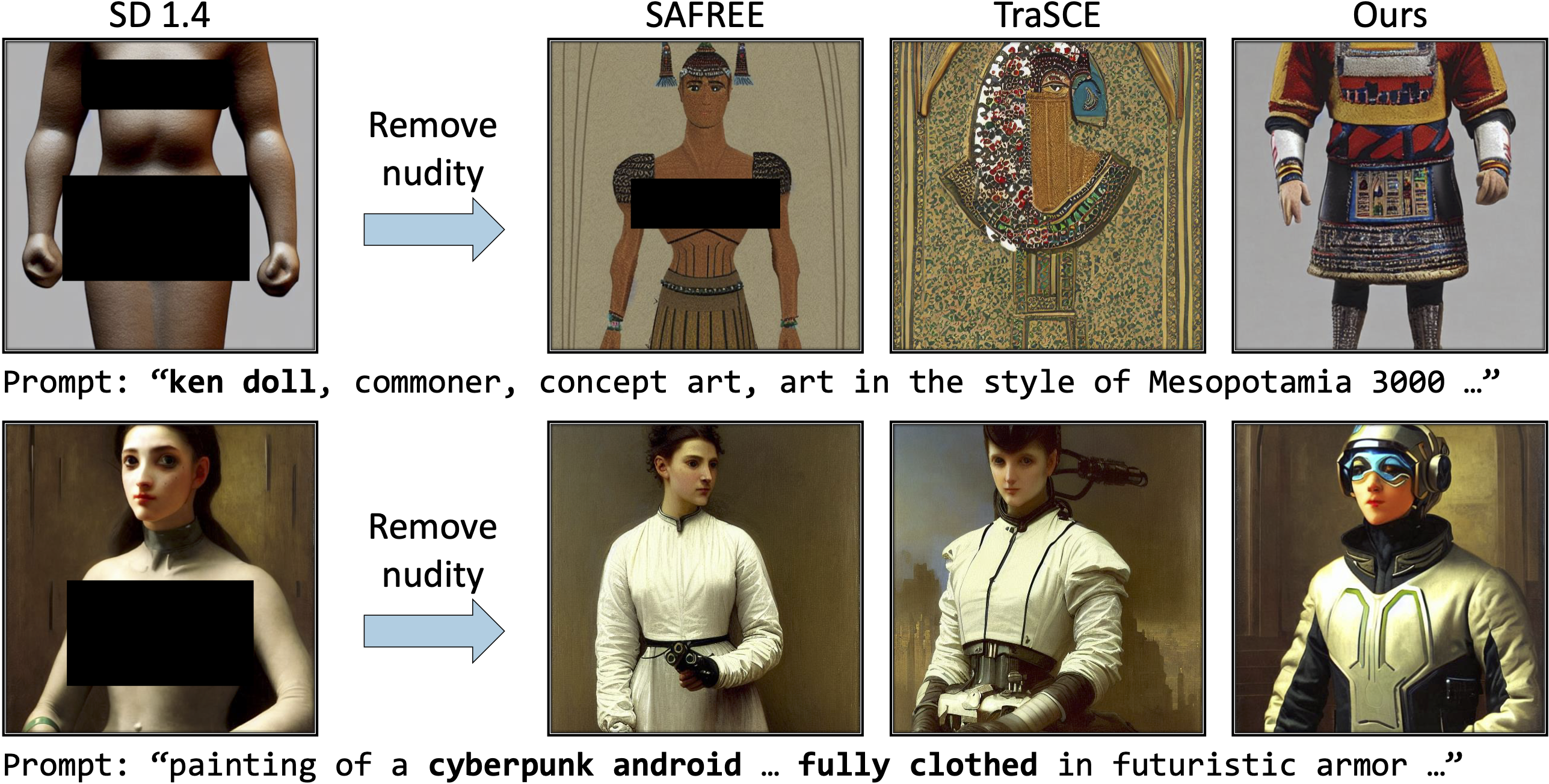
Qualitative comparisons of different approaches, including TraSCE and SAFREE, on the I2P dataset. Our method removes nudity without significantly altering the generated images, resulting in outputs that are better aligned with the input prompt.

Qualitative examples from the I2P dataset. Our method allows fine-grained control over the removal of specific concepts, removing only the intended concept while preserving the overall structure and style of the generated images.

Qualitative comparisons of different methods, including TraSCE and SAFREE, on the P4D dataset. The P4D dataset consists of adversarial prompts designed to challenge generative models. Our approach effectively removes the concept of nudity during the generation process, producing safe and semantically meaningful outputs. In contrast, SAFREE fails to generate safe images, while TraSCE sometimes produces unrelated outputs despite the presence of semantically meaningful keywords in given prompts, such as "girl," "roman," "renaissance," and "paintings" (middle row).


Qualitative example from the I2P dataset with FLUX. Our method is model-agnostic and can be applied to both U-Net-based SD 1.4 and SDXL-Turbo, as well as DiT-based FLUX.
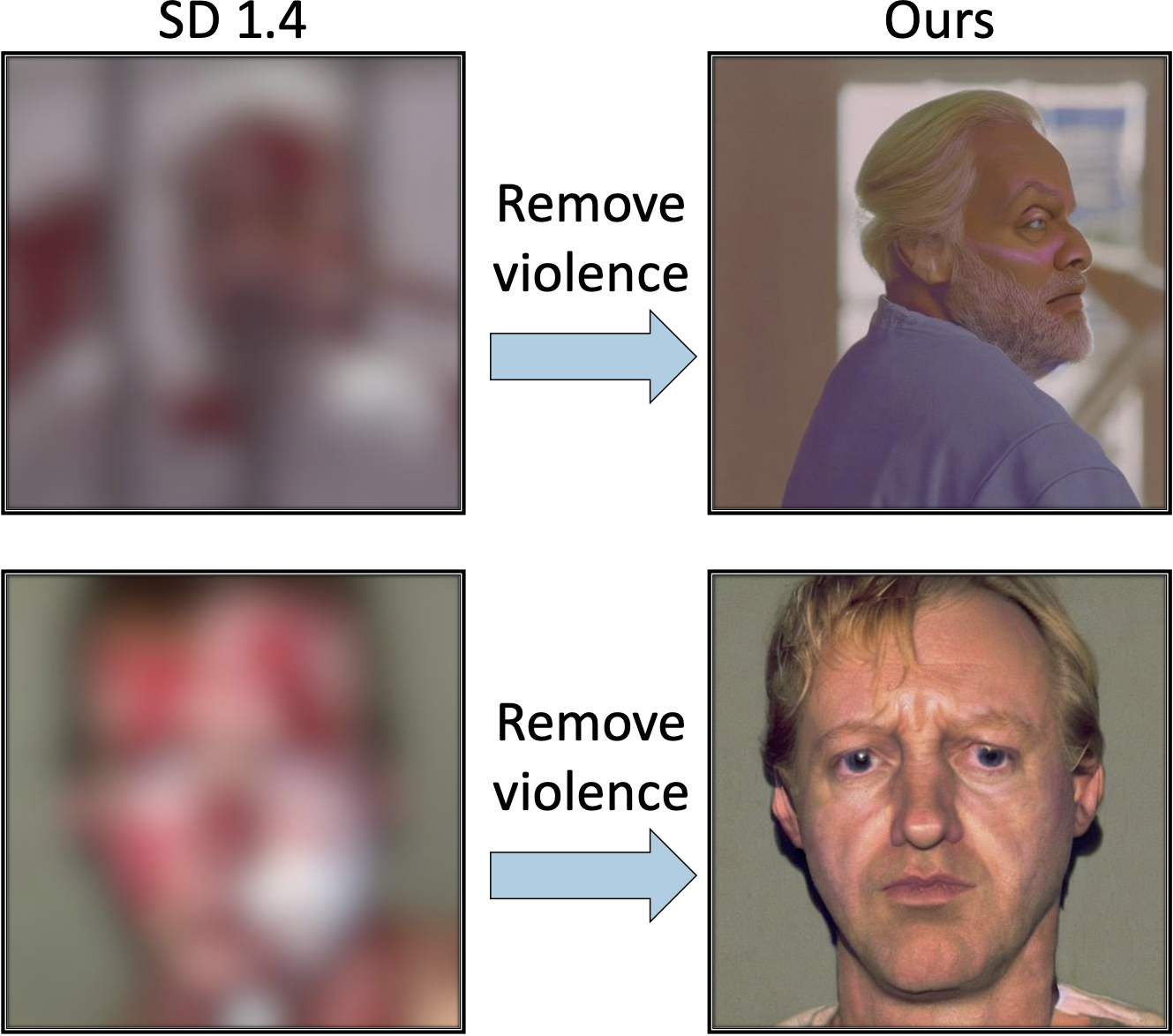

Qualitative examples from the Ring-A-Bell dataset. Our method successfully removes the abstract concept of violence, as shown by the absence of blood in the right images. The images are intentionally blurred for display purposes as they are disturbing.

Photographic style manipulation of SD 1.4 for the given prompt "geodesic landscape, john chamberlain, christopher balaskas, tadao ando, 4 k, " where concept prompts are "minimalist" (Top) and "zoom-in, magnify" (Bottom), respectively. In the top row, the image is manipulated toward a maximalist style as λ → -1, while it adopts a minimalist style as λ → 1. Similarly, in the bottom row, the image appears zoomed out and becomes blurred as λ → -1, whereas it becomes zoomed in and clearer as λ → 1.

Qualitative comparisons with weather Concept Sliders on SDXL-Turbo. Note that Concept Sliders train specific sliders: winter weather slider and a dark weather slider, whereas our method trains a k-SAE only once for different concepts. Top: "A photo of a tree with a bench, realistic, 8k" with concept to steer = "winter." Bottom: "A photo of a forest, realistic, 8k" with the concept to steer = "low light." Notice how in the top image our method also removes leaves while in the bottom image, our method effectively applies a low-light effect to the original image.
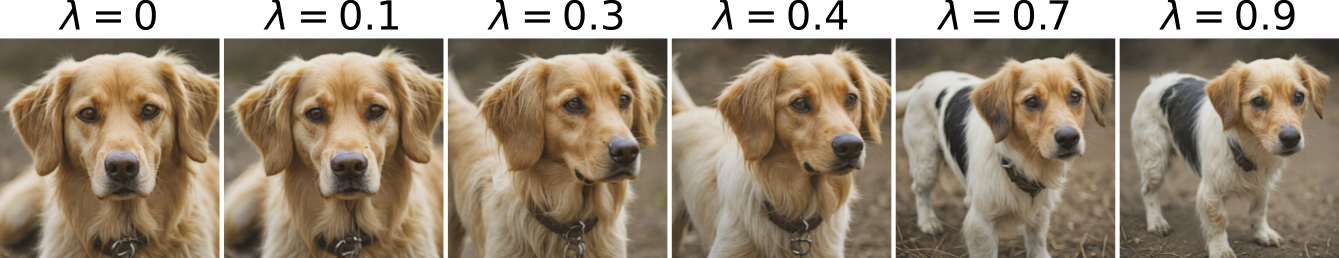
Image composition manipulation using SDXL-Turbo for the prompt "A dog" with the concept prompt "Full shot." Notice how as λ → 1, the generated image transitions from a close-up of the face to a full shot.


Object attribute manipulation of SDXL-Turbo for the given prompts "A car" (Top) and "A photo of a tree" (Bottom), where the concept prompts are "A blue car" (Top) and "Tree with autumn leaves" (Bottom). By adjusting λ, our method transitions the image toward the desired concept specified by the prompts.

Object attribute manipulation of SDXL-Turbo for the given prompts "A photo of a cake, 4k,"" where the concept prompts are "A chocolate cake," "A white cake," "A lemon cake," and "An orange cake," respectively. By adjusting λ, our method transitions the image toward the desired concept specified by the prompts.
@article{kim2025concept,
title={Concept Steerers: Leveraging K-Sparse Autoencoders for Controllable Generations},
author={Kim, Dahye and Ghadiyaram, Deepti},
journal={arXiv preprint arXiv:2501.19066},
year={2025}
}